
AWS’s own guidance is clear: split your workloads into multiple accounts. One account per environment, per team, per workload. The isolation boundaries are real — billing, IAM, service quotas, networking — and the benefits are genuine. Blast radius shrinks. Regulatory requirements become easier to demonstrate. Ownership gets cleaner on paper.
The problem is what happens six months after following that advice.
You end up with fifteen accounts, three different ways to provision a database depending on which team you ask, and a platform engineer spending their Fridays manually reconciling state across environments. The accounts didn’t create the chaos. The absence of a coherent control plane did.
The Tutorial Trap
Every operator tutorial starts the same way: one cluster, one team, one account. A Kubernetes operator (e.g., Crossplane or other alternatives) reconciles the desired state and creates AWS resources. It works well in that context. That’s not a design flaw. It’s a scope decision. The gap appears when that same model encounters an enterprise landing zone.
Real-world platforms must serve multiple teams simultaneously, span production and non-production environments, and satisfy security and regulatory requirements that no single operator was designed to enforce. The single-cluster model that works beautifully in a tutorial has no concept of Service Control Policies applied two levels up in an AWS Organizations hierarchy. It manages its slice of the world and nothing else. When ten teams each adopt that model independently, the result isn’t ten coherent platforms. It’s one incoherent one.
Four Places Where Complexity Actually Lives
The AWS account boundary encompasses four distinct boundary types: billing, IAM, service quotas, and networking. That’s intentional. But it means every architectural decision about account structure creates ripple effects across all four dimensions at once.
Identity is usually where teams feel the pain first. Cross-account role assumptions accumulate fast. Service Control Policies need to restrict enough to matter without breaking legitimate workflows. IAM Identity Center permission sets can be scoped to individual accounts rather than OUs, so the organizational unit structure doesn’t need to be architecturally perfect, but if the account topology doesn’t reflect how teams actually work, access governance becomes increasingly hard to reason about over time.
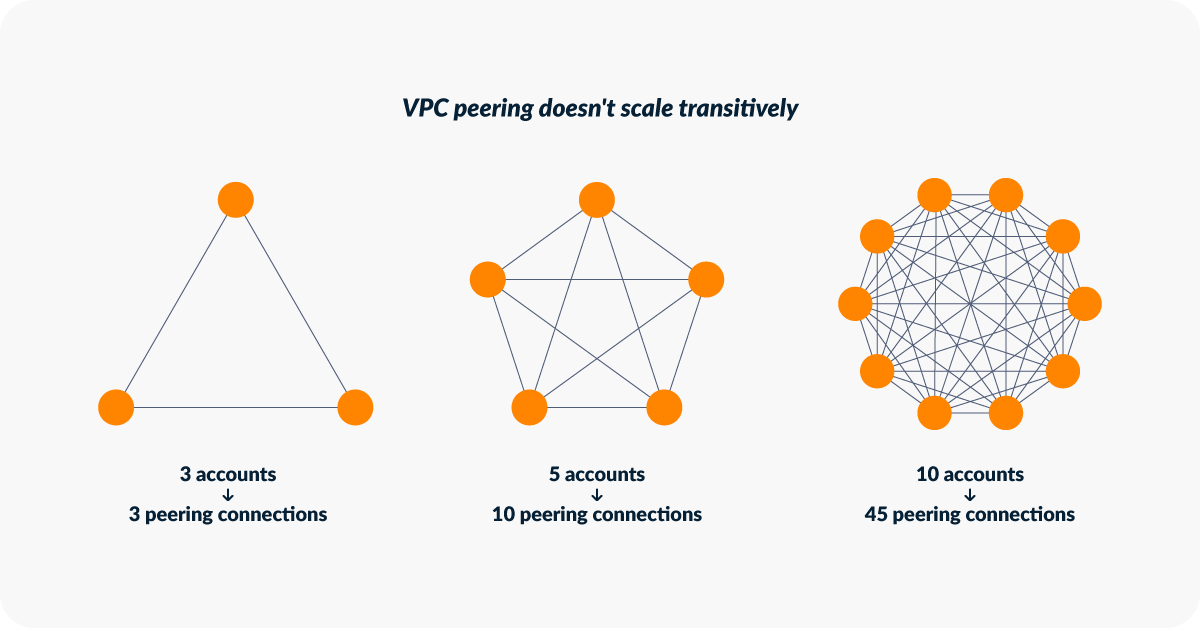
Networking compounds this. Separate accounts mean separate VPCs. Connecting them requires selecting between options that each carry real costs: VPC peering lacks transitivity, so three accounts needing communication require three peerings, and the connection count grows quadratically as the account estate expands. Transit Gateway addresses transitivity but adds per-attachment and per-GB costs that accumulate at scale. PrivateLink endpoints provide precise, service-level connectivity but are labor-intensive to manage across a large account estate. None of these is simply correct; they involve trade-offs that tend to be revisited as platforms grow.
Governance is the third dimension. Teams want (and reasonably expect) autonomy over their own resources. Without centralized enforcement of encryption standards, backup policies, and logging configuration, drift is inevitable. Not because teams are careless, but because there’s no mechanism to prevent it. A policy defined in one account has no reach into another.
And then there’s visibility. A recurring challenge in multi-account Kafka and database migrations is that technical provisioning of services across accounts is tractable; maintaining operational consistency and audit visibility across that account estate afterward is more difficult. Without a unified view, platform teams are flying blind on compliance status, backup health, and upgrade readiness across accounts they nominally govern.
Why Managed Services Don’t Resolve This
RDS, Aurora, MSK, and ElastiCache, as AWS-managed services, genuinely reduce provisioning complexity. But they don’t cross account boundaries on behalf of the teams using them.
A pattern that consistently emerges when platform teams try to solve cross-account database access: the first attempt uses VPC peering, which exposes more network surface area than security requirements allow. The second attempt introduces a Lambda function per account to mediate access, which works until the number of accounts grows, resulting in a distributed system of IAM roles and functions that nobody fully owns. Switching to the Aurora Data API removes the network dependency but introduces its own constraints: it’s limited to Aurora Serverless configurations, uses an HTTP-based protocol with higher latency than direct database connections, and doesn’t support long-running transactions.
These aren’t bad decisions. They’re the tools competent engineers reach for when platform-level abstractions are missing. However, each choice adds silent costs-ongoing maintenance, inconsistent environments, and a widening gap between what the platform claims to provide and actual team experience.
Managed services are excellent primitives. They are not a control plane.
Why Operators Don’t Resolve This Either
Crossplane is a sound technology for writing backend integrations connecting Kubernetes desired-state declarations to AWS APIs. At the control-plane level, it’s a reasonable choice for that purpose. The problem arises when it’s used as a client extension across hundreds of application clusters.
Each Crossplane installation carries meaningful CRD overhead. Across a marketplace of 15 database types running on 500 application clusters, that overhead becomes a real operational constraint. Major version upgrades force simultaneous upgrades across all integrations manageable with a small surface area, but increasingly painful as the number of backends grows.
Beyond resource overhead, there’s a more fundamental issue. An operator managing resources within one account doesn’t have the organizational context to enforce guardrails that belong at the AWS Organizations level. For EKS-based setups, IRSA or EKS Pod Identity eliminates the need for static credentials and enables properly scoped, short-lived role assumptions. But even with clean credential management in place, the cross-account scope problem remains. Governance at the organizational level requires thinking at that level—not at the cluster level.
AWS draws a useful distinction between control planes (administrative APIs and orchestration systems) and data planes (service runtime). Control-plane impairments don’t necessarily affect running workloads, but they prevent new deployments and block recovery operations. In a multi-account setup, each account has its own control plane, and integrating them is a design problem that cluster-level operators aren’t positioned to solve.
What the Architecture Actually Needs to Look Like
The control-plane design problem has a recognizable shape once you’ve seen it enough times. What’s needed isn’t a heavier operator. It’s a layer that sits above the cluster, understands the account topology, and serves as the authoritative orchestration point across it.
Concretely: provisioning logic needs to be coupled with policy enforcement, not decoupled from it. Developers need a consistent interface for requesting resources, regardless of which account those resources land in; the account topology should be an implementation detail, not something each team navigates independently. Lifecycle management needs to be defined once and applied consistently across all accounts, because the failure mode otherwise isn’t absence but inconsistency. And the platform team needs cross-account visibility that reflects the actual operational reality: backup health, quota utilization, and compliance status, not just what’s visible from a single authenticated session.
One architecture that meets these requirements uses a federated model: a single control plane per region, running on a dedicated Kubernetes cluster, paired with lightweight extensions deployed to each application cluster. The extensions are small enough that a set of CRDs installable via Helm or Kustomize can run across hundreds of clusters without significant resource overhead. The control plane holds the organizational context: it knows which AWS accounts belong to which tenant, and when a developer provisions a service from their application cluster, the control plane assumes the appropriate IAM role in the target service account via STS and creates the instance where it belongs. The platform team retains a centralized view across the full account estate.
This is the model a9s Hub for AWS implements, built on the open-source Klutch project. Klutch uses Crossplane at the control-plane level for backend integrations, RDS, and S3 today, with additional backends added as modular integrations while keeping the application-cluster extension deliberately lightweight. The tenant model maps directly to the account-pair pattern that emerges consistently in Well-Architected Framework deployments: one EKS account and one service account per tenant, repeated across the organization. For teams with existing AWS topologies, migration tooling to import that structure into the control plane is in development.
The Real Cost of Distributing Complexity
When there’s no coherent control plane, complexity doesn’t disappear; it distributes. Each team absorbs a portion of it. Some build their own operator configurations. Some write custom scripts for cross-account access. Some maintain separate runbooks that slowly diverge from one another. The platform team handles one-off requests rather than building platform capabilities. The Friday reconciliation becomes a permanent fixture.
Multi-account AWS done well isn’t a function of how many accounts an organization has. It’s a function of whether the control-plane logic governing those accounts is coherent, understands the account topology, enforces policy at the point of provisioning, and provides developers with a consistent interface regardless of what’s happening underneath.
The teams that treat that as a design decision from the start, rather than a problem to address once things have already broken down, tend to build platforms that hold together as they scale. The others get very good at debugging state drift on Friday afternoons.







